并行设计¶
gsmpi中的gs是gather、scatter的缩写。流体部分的并行包括虚拟网格数据的交互以及傅里叶变化中pencil数据交互两个部分,这里只介绍虚拟网格数据的交互,傅里叶变化中pencil数据交互请查看三维傅里叶变换与pencil并行 – tfft3d部分。
并行拓扑关系基础¶
程序的并行初始化在主程序中进行,即MPI_Init(nullptr, nullptr);,而并行初始化设置在主程序中由流体求解器调用函数fluidsol.ConfigDataSpaceDict();触发。函数ConfigDataSpaceDict()定义在CartDataSpace类中,该函数调用gsmpi::GSMPICart<N_dim>类中的InitMPI(nprocs, isperoid)函数进行并行初始化设置,包括定义在GSMPI类中的:
初始化通信域
_comm获得当前进程的的进程标识
_rank检查是否正确设置总进程数
_nprocall
以及定义在gsmpi::GSMPICart<N_dim>类中的:
获得当前进程在三维笛卡尔坐标系中的进程标识
_coord[N_dim]获得当前进程的邻居进程总数
_num_nbrs获得不包含当前进程和空进程的邻居进程总数
_num_nbrs_exclude_null_selfproc获得当前进程的邻居进程标识的列表
_nbrs初始化图通信域
_graph_index、_graph_edge、_valid_nbrs_order
最终的通信域_comm附加了图拓扑关系,_nbrs包含所有的邻居进程(自身进程和空进程),_valid_nbrs_order只包含有效邻居进程。
并行数据结构¶
并行数据结构部分主要涉及颗粒的数据在不同进程之间的传输,目前有两个版本共存共用的,旧版本由GSMPIPData和SendRecvModel类共同完成,下面分别对两个版本进行介绍。
旧版本——
GSMPIPData数据类型为单精度或双精度:
static inline MPI_Datatype GSMPI_REAL = MPI_FLOAT; static inline MPI_Datatype GSMPI_REAL = MPI_DOUBLE;
旧版本的数据类型,包含实数和整数(颗粒的
id):template <int N_real, typename T_real, int N_int, typename T_int> struct GSMPIPData { T_real data[N_real]; T_int partid[N_int]; inline auto getNreal() { return N_real; } inline auto getNint() { return N_int; } };
特例化的数据类型,目前旧版本的类型限定了颗粒数据使用的上限,三维和二维的分别为33和19,用于真正存储颗粒数据的类型:
using MPIPData3DBasicD = GSMPIPData<33, double, 3, unsigned int>; using MPIPData2DBasicD = GSMPIPData<19, double, 3, unsigned int>; using MPIPData3DFluidD = GSMPIPData<32, double, 3, unsigned int>; using MPIPData2DFluidD = GSMPIPData<18, double, 3, unsigned int>; static MPIPData3DBasicD mpipdata_3d_basic_d; static MPIPData2DBasicD mpipdata_2d_basic_d; static MPIPData3DFluidD mpipdata_3d_fluid_d; static MPIPData2DFluidD mpipdata_2d_fluid_d;
用于在不同进程传接数据的类型
MPIPDATA_3D_BASIC_D、MPIPDATA_2D_BASIC_D:static inline MPI_Datatype MPIPDATA_3D_BASIC_D = nullptr; static inline MPI_Datatype MPIPDATA_2D_BASIC_D = nullptr; static inline MPI_Datatype MPIPDATA_3D_FLUID_D = nullptr; static inline MPI_Datatype MPIPDATA_2D_FLUID_D = nullptr;
static void CommitMPIPData() { MPI_Datatype type[2] = {MPI_DOUBLE, MPI_UNSIGNED}; GSMPI_PDATA_COMMIT(MPIPData3DBasicD, MPIPDATA_3D_BASIC_D) GSMPI_PDATA_COMMIT(MPIPData2DBasicD, MPIPDATA_2D_BASIC_D) GSMPI_PDATA_COMMIT(MPIPData3DFluidD, MPIPDATA_3D_FLUID_D) GSMPI_PDATA_COMMIT(MPIPData2DFluidD, MPIPDATA_2D_FLUID_D) } inline static void FreeMPIPData() { GSMPI_PDATA_FREE(MPIPDATA_3D_BASIC_D) GSMPI_PDATA_FREE(MPIPDATA_2D_BASIC_D) GSMPI_PDATA_FREE(MPIPDATA_3D_FLUID_D) GSMPI_PDATA_FREE(MPIPDATA_2D_FLUID_D) } #define GSMPI_PDATA_COMMIT(PDataName, MPIPDATANAME) \ { \ PDataName temp; \ int blocklen[2] = {temp.getNreal(), temp.getNint()}; \ MPI_Aint disp[2]; \ MPI_Aint base_address; \ MPI_Get_address(&temp, &base_address); \ MPI_Get_address(&temp.data[0], &disp[0]); \ MPI_Get_address(&temp.partid[0], &disp[1]); \ disp[0] = MPI_Aint_diff(disp[0], base_address); \ disp[1] = MPI_Aint_diff(disp[1], base_address); \ MPI_Type_create_struct(2, blocklen, disp, type, &MPIPDATANAME); \ MPI_Type_commit(&MPIPDATANAME); \ } #define GSMPI_PDATA_FREE(MPIPDATANAME) MPI_Type_free(&MPIPDATANAME);
旧版本的——
SendRecvModel类:本类主要被设计为颗粒进行不同进程间传输和接收数据前进行数据的准备,将要传输的数据存储在SendRecvModel类的
buffer变量中,最后调用gsmpi::GSMPICart<N_dim>中的SendRecv、SendRecv_v1、AllGather函数进行传输和接收,各个进程接收数据后再将收到的数据放在自己进程的变量中。数据
Array1<T> buffer; // buffer for sending data int num_of_blocks; // the number of sending or receiving blocks int len; // length of the buffer Array1i counts; // the count of data for each sending or receving block Array1i disps; // the displacement of data for each sending or receiving block Array1i inds; // record the current position of the data for each sending or receiving block
其中的
num_of_blocks一般是当前进程的有效邻居进程总数。方法
设置
num_of_blocksinline auto &setNumBlocks(const int num) { num_of_blocks = num; return *this; }
插入
buffer前初始化indsinline auto &InsertBufferInit() { inds = 0; return *this; }
将数据插入
bufferinline auto &InsertBuffer(const int i, const T &val) { buffer(disps(i) + inds(i)) = val; inds(i)++; return *this; }
设置每个block的大小
inline auto &setCounts(const int scounts[]) { for (auto i = 0; i < num_of_blocks; ++i) { counts(i) = scounts[i]; } return *this; }
更新缓冲区
buffer的大小inline auto &UpdateLen() { len = sum(counts); return *this; }
为缓冲区分配空间
inline auto &AllocateBuffer() { if (len == 0) { // for an new empty buffer, the length of buffer should be 10 at least buffer.resizeAndPreserve(10); } else if (len > buffer.size()) { // if new length of buffer is larger than the current length of buffer buffer.resizeAndPreserve(len + len / 2); // the length should be extend to 1.5 times of the old one. } else if (len < buffer.size() / 2 & buffer.size() > 10) { // if new length of buffer is much smaller than the current length of buffer buffer.resizeAndPreserve(len + len / 2); // the length should be cut up and preserve 1.5 times of the new length } return *this; }
计算每个block在
buffer中的起始位置inline auto &PrepareDisp() { disps(0) = 0; for (auto i = 1; i < num_of_blocks; ++i) { disps(i) = disps(i - 1) + counts(i - 1); } return *this; }
打印
buffer中的内容inline auto &PrintBuffer() { for (auto i = 0; i < len; ++i) { std::cout << buffer(i) << "\t"; } std::cout << std::endl; return *this; }
派生类的
Sender类、Receiver类:template <typename T> struct Sender : public SendRecvModel<T> { Sender() {} Sender(const int num) { SendRecvModel<T>::Init(num); } }; template <typename T> struct Receiver : public SendRecvModel<T> { Receiver() {} Receiver(const int num) { SendRecvModel<T>::Init(num); } };
特例化的
Sender类、Receiver类:static Sender<MPIPData3DBasicD> mpipdata3d_send; static Receiver<MPIPData3DBasicD> mpipdata3d_recv; static Sender<MPIPData2DBasicD> mpipdata2d_send; static Receiver<MPIPData2DBasicD> mpipdata2d_recv; static Sender<int> int_send; static Receiver<int> int_recv;
旧版本的颗粒数据传输初始化与准备(主要是初始化当前进程的邻居数目):
template <int N_dim> static inline void InitMPIPData(const int nblock) { if constexpr (N_dim == 3) { gsmpi::mpipdata3d_send.Init(nblock); gsmpi::mpipdata3d_recv.Init(nblock); } else if constexpr (N_dim == 2) { gsmpi::mpipdata2d_send.Init(nblock); gsmpi::mpipdata2d_recv.Init(nblock); } }
新版本
SerializedBuffer:数据类型为
union,union可以有多个数据成员,但是在任意时刻只有一个数据成员可以有值,其他成员是未定义的状态,且分配给一个union对象的存储空间至少要能容纳它的最大的数据成员:union SerializedData { int intVal; double realVal; unsigned int uintVal; };
数据
// buffer for sending data, T = double or int Array1<SerializedData> buffer; // the number of sending or receiving blocks int num_of_blocks; // length of the buffer int len; // the count of entry for each sending or receving block Array1i counts; // the displacement of data at the beginning of each sending or receiving block Array1i disps; // length of each block Array1i block_len; // points to the current record position of buffer (each block) Array1i _ptr;
方法:
设置传输的
block的数目,分配空间并初始化:void SetBlockNum(int blockNum) { num_of_blocks = blockNum; len = 0; counts.resize(blockNum); counts = 0; _ptr.resize(blockNum); disps.resize(blockNum); disps = 0; block_len.resize(blockNum); block_len = 0; }
记录每个
block中的条目计数和block的长度void Register(int block, int entrylen) { // record the count of entry in each block, and the block size counts(block)++; block_len(block) += entrylen; }
重置
bufferinline void ResetBuffer() { ResetPtr(); len = 0; disps = 0; block_len = 0; counts = 0; } inline void ResetPtr() { _ptr = 0; }
设置
buffer的长度len和每个block的起始位置,并为其分配空间:SerializedBuffer &SetBuffer() { len = 0; for (int i = 0; i < block_len.size(); i++) { disps(i) = len; // set the begin position of each block len += block_len(i); } AllocateBuffer(len); _ptr = 0; return *this; }
为
buffer分配空间:inline void AllocateBuffer(int length) { if (length == 0) { // for an new empty buffer, the length of buffer should be 10 at least buffer.resizeAndPreserve(10); } else if (length > buffer.size()) { // if new length of buffer is larger than the current length of buffer buffer.resizeAndPreserve(length + length / 2); // the length should be extend to 1.5 times of the old one. } else if (length < buffer.size() / 2 & buffer.size() > 10) { // if new length of buffer is much smaller than the current length of buffer buffer.resizeAndPreserve(length + length / 2); // the length should be cut up and preserve 1.5 times of the new length } }
往
buffer中添加数据inline void Add(int block, const int data) { buffer(_ptr(block) + disps(block)).intVal = data; _ptr(block)++; } inline void Add(int block, const unsigned int data) { buffer(_ptr(block) + disps(block)).uintVal = data; _ptr(block)++; } inline void Add(int block, const double data) { buffer(_ptr(block) + disps(block)).realVal = data; _ptr(block)++; } inline void AddArr(int block, const Array1r &arr) { unsigned int size = arr.size(); Add(block, size); // add size for (auto i = 0; i < arr.size(); i++) { Add(block, arr(i)); } }
从
buffer中获取数据inline void Get(int block, int &data) { data = buffer(_ptr(block) + disps(block)).intVal; _ptr(block)++; } inline void Get(int block, unsigned int &data) { data = buffer(_ptr(block) + disps(block)).uintVal; _ptr(block)++; } inline void Get(int block, double &data) { data = buffer(_ptr(block) + disps(block)).realVal; _ptr(block)++; } inline void GetArr(int block, Array1r &arr) { unsigned int size = 0; Get(block, size); // read size arr.resize(size); // set array for (auto i = 0; i < arr.size(); i++) { Get(block, arr(i)); } }
颗粒并行¶
下面主要介绍颗粒并行操作流程:
颗粒部分的并行设置在主程序中由颗粒求解器调用函数
ppsol.SetMPI();触发,获得当前进程的邻居进程所负责区域的大小,并为颗粒数据的传输进行设置psendbuff.SetBlockNum(nblock);、precvbuff.SetBlockNum(nblock);、gsmpi::InitMPIPData<N_dim>(nblock);和gsmpi::CommitMPIPData();,同时初始化要传输的颗粒数目sendcounts.resize(nblock);和virtsendcounts.resize(nblock);。在每次颗粒求解前,初始化颗粒的传输数
sendcounts = 0;。求解时如果考虑颗粒之间的相互作用,则在求解前准备好“虚拟”颗粒
PrepareSendRecvForVirtualRegion(partfieldlist);,准备好后就可以进行传送VirtualParticleSendRecv(partfieldlist);。
流体并行¶
流体虚拟网格数据的交互主要在CartFieldGhostComm类中实现,由主程序中的流体求解器调用函数fluidsol.Init();进行触发,Init()函数定义在各自的流体求解器内部,Init()函数调用ghostcomm.Init(mpicomm);进行初始化,再调用ghostcomm.AllocateBuffer(mesh_size, ghost_size);分配需要传输数据的空间,准备好后就可以进行数据的传输交互了。注意有的流体求解器可能不需要虚拟网格数据传输。下面简单介绍CartFieldGhostComm类,本类是模板类,模板参数为<typename T, int N_dim>:
数据
MPI_Comm _comm; // mpi communicator Array1<T> buffer; // buffer for sending data Array1<T> recv_buffer; // 目前没有使用 int count = 0; // the count of data for each sending/receving block Array1i nbrs; // the list of neighboring rank int nbrs_num; // the number of neighboring rank
方法
初始化
inline auto &Init(GSMPICart<N_dim> &comm) { nbrs_num = comm.GetNumofNbrs(); // std::cout<<nbrs_num<<std::endl; count = 0; nbrs.resize(nbrs_num); auto ptr = comm.PtrNbrsList(); for (auto i = 0; i < nbrs_num; ++i) { nbrs(i) = *(ptr + i); } _comm = comm.GetComm(); return *this; }
设置虚拟网格数据交互的通信域
_comm(其实和GSMPI类中的通信域_comm是完全一样的)、设置当前进程的邻居数目nbrs_num和邻居列表nbrs、初始化传送和接收的数据大小count。分配交互数据buffer大小(包含虚拟网格部分)
inline auto &AllocateBuffer(std::vector<int> size, std::vector<std::vector<int>> ghost_size) { int sum = 1; for (auto i = 0; i < N_dim; ++i) { sum *= size[i] + 1 + ghost_size[i][0] + ghost_size[i][1]; } int maxsum = 0; for (auto i = 0; i < N_dim; ++i) { maxsum = std::max(maxsum, sum / (size[i] + 1 + ghost_size[i][0] + ghost_size[i][1])); } int maxghost = 0; for (auto i = 0; i < N_dim; ++i) { maxghost = std::max(maxghost, std::max(ghost_size[i][0], ghost_size[i][1])); } int maxlen = maxghost * maxsum; // 相对保守的设置,预留了尽可能大的空间 buffer.resize(maxlen); return *this; }
传送数据 通过调用
ghostcomm.SendRecv(block.u.data, ghost_size, gsmpi::GSMPI_REAL);函数实现。该函数主要调用其他SendRecvAlongX、SendRecvAlongY、SendRecvAlongZ函数进行实现,其中以SendRecvAlongX为例,其实现的的数据传输如下图所示: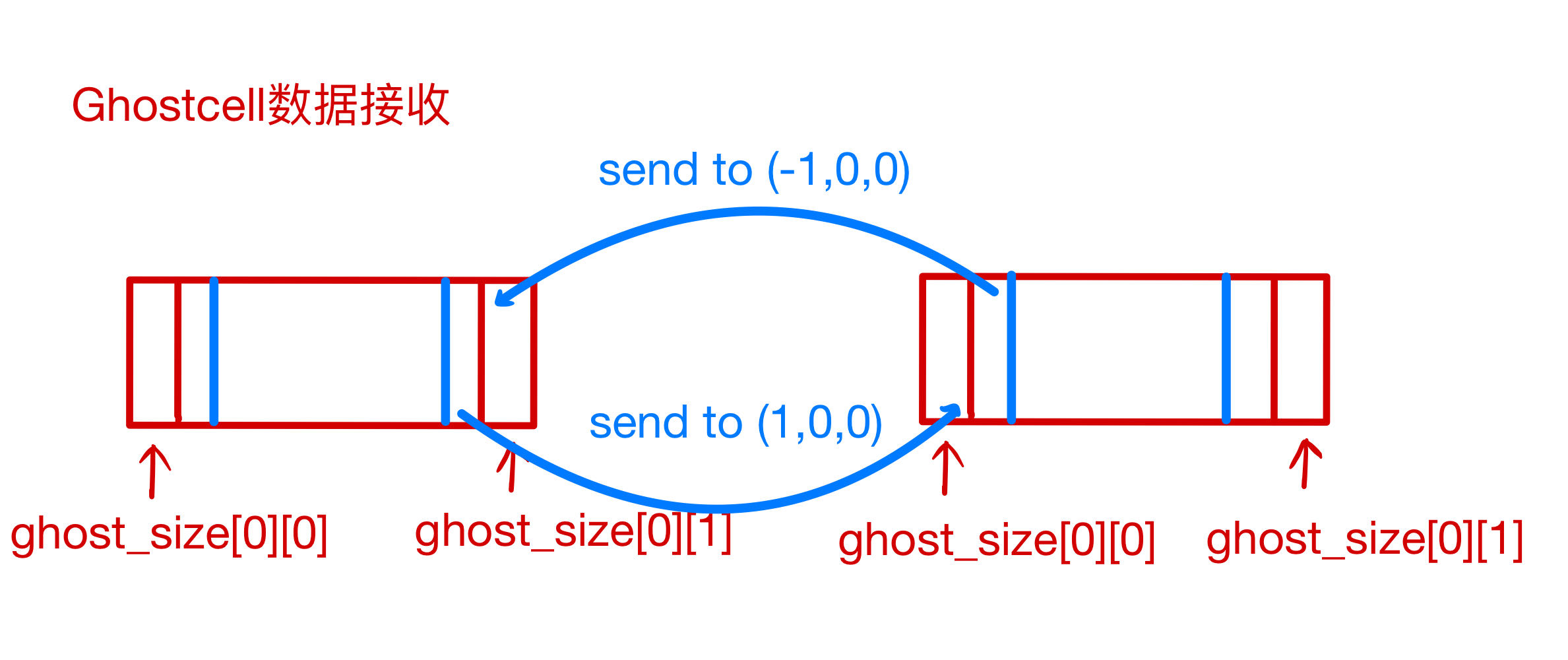
具体代码比较清晰,如下所示:
// comm in x rank0 = nbrs(0 + 1 + 3 * ((0 + 1) + 3 * (-1 + 1))); //(-1,0,0) rank1 = nbrs(0 + 1 + 3 * ((0 + 1) + 3 * (1 + 1))); //(1,0,0) // count=totalsize[1]*totalsize[2]*ghost_size[0][1]; // send data to the neighbor (-1,0,0) // prepare the data will be sent in the buffer count = totalsize[1] * totalsize[2] * ghost_size[0][1]; int loc = 0; for (auto i = ghost_size[0][0]; i < ghost_size[0][0] + ghost_size[0][1]; ++i) { for (auto j = 0; j < totalsize[1]; ++j) { for (auto k = 0; k < totalsize[2]; ++k) { buffer(loc) = data[k + totalsize[2] * (j + totalsize[1] * i)]; loc++; } } } MPI_Sendrecv_replace(buffer.data(), count, datatype, rank0, 100, rank1, 100, _comm, MPI_STATUS_IGNORE); // place the received data in the ghost part loc = 0; for (auto i = totalsize[0] - ghost_size[0][1]; i < totalsize[0]; ++i) { for (auto j = 0; j < totalsize[1]; ++j) { for (auto k = 0; k < totalsize[2]; ++k) { data[k + totalsize[2] * (j + totalsize[1] * i)] = buffer(loc); loc++; } } } // send data to the neighbor (1,0,0) // prepare the data will be sent in the buffer count = totalsize[1] * totalsize[2] * ghost_size[0][0]; loc = 0; for (auto i = totalsize[0] - ghost_size[0][0] - ghost_size[0][1]; i < totalsize[0] - ghost_size[0][1]; ++i) { for (auto j = 0; j < totalsize[1]; ++j) { for (auto k = 0; k < totalsize[2]; ++k) { buffer(loc) = data[k + totalsize[2] * (j + totalsize[1] * i)]; loc++; } } } MPI_Sendrecv_replace(buffer.data(), count, datatype, rank1, 101, rank0, 101, _comm, MPI_STATUS_IGNORE); // place the received data in the ghost part loc = 0; for (auto i = 0; i < ghost_size[0][0]; ++i) { for (auto j = 0; j < totalsize[1]; ++j) { for (auto k = 0; k < totalsize[2]; ++k) { data[k + totalsize[2] * (j + totalsize[1] * i)] = buffer(loc); loc++; } } }